Disaster Recovery
Anava maintains comprehensive disaster recovery procedures to ensure platform resilience and business continuity.
Overview
Our Disaster Recovery (DR) Plan addresses SOC2 Trust Services Criteria:
- CC7.4 - Detection, monitoring, and response to security incidents
- CC7.5 - Identification and recovery from identified incidents
Recovery Objectives
| Metric | Target | Description |
|---|---|---|
| RTO | 4 hours | Maximum acceptable downtime for critical services |
| RPO | 1 hour | Maximum acceptable data loss |
| MTPD | 24 hours | Maximum tolerable period of disruption |
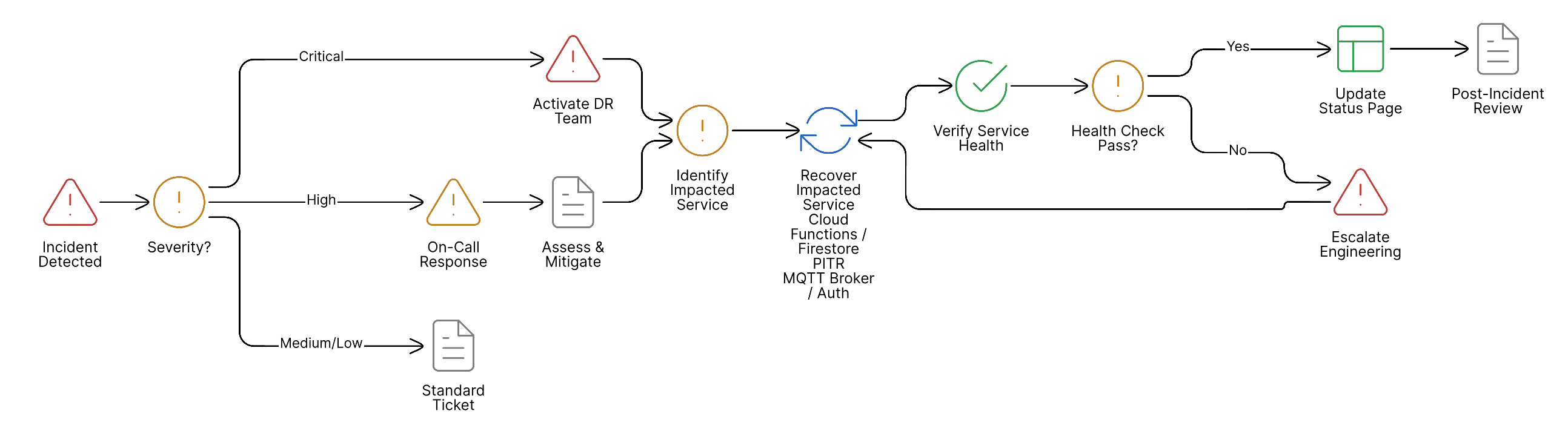
Disaster Recovery Flow
The following diagram illustrates the disaster recovery decision process:
Key Capabilities
Multi-Layer Redundancy
- Firebase services with automatic failover
- MQTT broker with container-based recovery
- Firestore point-in-time recovery (PITR)
- Versioned Terraform state backups in GCS
- Multi-region Cloud Functions deployment
Infrastructure Recovery
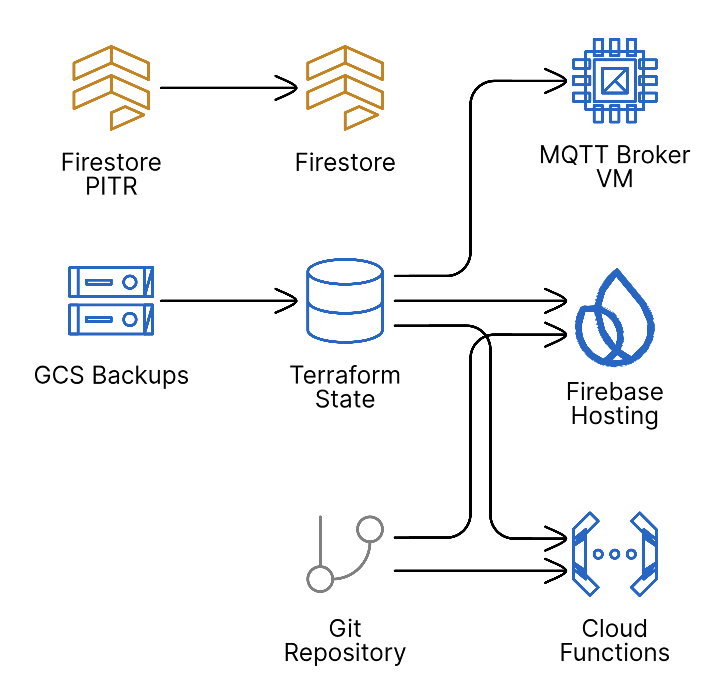
Monitoring and Alerting
- Cloud Monitoring for infrastructure health
- Automated uptime checks every 60 seconds
- Connection anomaly detection via MQTT metrics
- Security event correlation with Cloud Logging
- PagerDuty integration for on-call alerting
Communication
- Defined escalation procedures
- Customer notification templates
- Status page integration at status.anava.ai
Recovery Procedures by Component
| Component | Recovery Method | RTO | RPO |
|---|---|---|---|
| Cloud Functions | Redeploy from CI/CD | 15 min | 0 |
| Firestore | Point-in-time recovery | 2 hours | 1 hour |
| MQTT Broker | Container restart/recreate | 30 min | 0 |
| Firebase Hosting | Redeploy from Git | 10 min | 0 |
| Terraform State | Restore from GCS backup | 1 hour | Daily |
Detailed Procedures
Internal Documentation
Detailed recovery runbooks, specific commands, and escalation matrices are available in the Internal Documentation.
Team members can sign in with their @anava.ai email to access these procedures.
Related Documents
- Security Overview - Security architecture
- Compliance - SOC2 controls
- SLA/SLO Targets - Service level agreements